
やあみんな、ビリーだよ。
今回は、メモリの使いかたについて説明してみよう。
これまでにビリーが講義した、
「七の巻:スタックってなあに?」
「八の巻:メモリを壊してみましょう」
「拾壱の巻:コードサイズを聞かれたら」
で復習しておくと、さらに理解度アップだよ!
セクションとヒープ領域とスタック領域
プログラムの本、コンパイラのマニュアルなどを見ていると、ヒープ領域やスタック領域という言葉が出て来るよね。これはいったい何だろう?メモリの領域をさしているようだけど、「拾壱の巻:コードサイズを聞かれたら」で解説した、セクションとは違うのかな?『セクション』は、ROMやRAMをどのような用途に使うかを決めるものなんだ。「プログラム(コード)を配置する領域」「データを配置する領域」などだね。
組込みの世界では、一般的にプログラムやOSをコンパイル(リンク)した時点でセクションのアドレスとサイズが決まっていて、動作中にセクションのアドレスやサイズが変わることは無いんだ。これに対して、『ヒープ領域』や『スタック領域』は、プログラム中で一時的に使用するメモリのことで、普通はRAM上のどこかのセクションの一部に属することになる。
『ヒープ領域』は、アプリケーションやOSで動的に割り当てたり解放するものなんだ。プログラムで一時的に必要になるメモリで、例えばファイルを読み出すときに読みだしたファイル内容を置いておいたり、ネットワークでデータを送受信する時にデータを置いておく時に使うよ。
必要な時に動的に確保し、使い終わったら解放することで、限られたメモリを有効に使うことができるね。malloc()という関数でメモリを割り当て、free()という関数で解放するのが標準的な方法なんだ。

左のような関数を実行すると、100バイトの領域がメモリ中のどこかにヒープとして確保されることになるんだ。
どこに確保されるかはmalloc(100)を実行した時点で決まるので前もって知ることはできないけど、data1 という変数にこのヒープ領域のアドレスが格納されるので、これでアドレスを知ることができるんだ。
『スタック領域』はコンパイラやOSが割り当て、アプリケーションでは自由に操作できない領域だ。プログラムが内部的にデータを保存しておく必要がある場合に、スタック領域が使用されるよ。
このほか、C言語でプログラムを作る場合などでは「自動変数」と呼ばれるものがあって (オート変数、スタック変数等とも呼ばれる)、スタックに配置される変数があるんだ。

左のような関数を作った場合、data1やdata2は通常スタック上に配置される。
ヒープ領域はメモリ上のどこかの場所に確保されるわけだけど、どのアドレスになるかは OS、開発環境(コンパイラ、リンカ)の他、製作するプログラムによるので、同じCPUを使っていれば必ず特定のアドレスになる、というものではないんだ。
例えば、あるOS/コンパイラの組み合わせでは、メモリ(RAM)は以下のように使用される。このような、メモリのアドレスと用途を表した図をメモリマップと呼ぶんだ。(VECT)や(C)などがOS、コンパイラなどによって「セクション」と呼ばれるものだ。
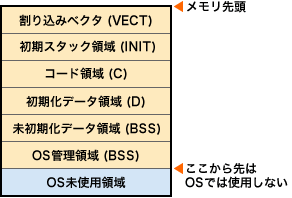
左図のようなメモリ配置の場合、「ヒープ領域」は「OS管理領域」の中にその一部として存在する。
このようなメモリ配置の場合、コード、初期化データ、未初期化データの各領域は製作するプログラムによってサイズが変わるため、OS管理領域のサイズや開始アドレスもこれによって 変わってくるんだ。
ショートコラム:「OS未使用領域」とは??
さっきのメモリマップに出てきた「OS未使用領域」とは、何だろう?未使用なので、使われない?ここでいう「OS未使用領域」とは、OSの管理下にはおかず、アプリケーションが自由に使用できる領域のことを指すんだ。OSやコンパイラ(リンカ)の設定でこのような領域を作ることができるよ。
ではわざわざ「未使用領域」を設けるメリットって、何だろう?
答えはいくつかあるのだけど、最大のメリットは、OSからヒープ領域を割り当ててもらう方式とは違って、プログラムから読み書きするアドレスを決め打ちできることなんだ。OSからmallocなどを使ってメモリを割り当てると、毎回アドレスが同じになるとは限らない。
一方、未使用領域をアプリケーションで直接使う場合は、必ず同じアドレスを使用することができる。マルチタスクでプログラムを組む場合に、複数のタスクでメモリを共有する時は、事前にアドレスが分かっていると便利だね。

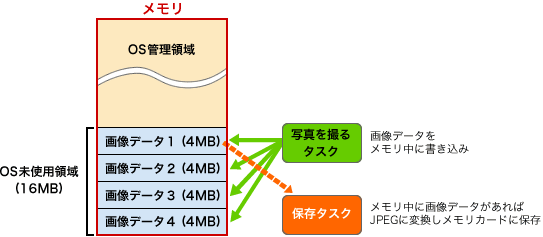
例えば、デジタルカメラで写真を撮ってメモリカードに保存することを考えてみよう。
単純に設計すると、写真を撮って、JPEGなどのファイル形式に変換して、メモリカードに画像を保存する、ということになる。ファイル変換とメモリカードの保存の処理は時間がかかるから、連続で写真を撮りたくても、保存が終わるまで次の写真を撮ることができないね。そこで、「写真を撮る」タスクと「ファイル変換しメモリカードに画像を保存する」タスクを別にすることにしよう。
1枚の画像で4MBのサイズがあるとして考えるよ。「OS未使用領域」として、写真4枚分、16MBの領域を設定する。「写真を撮る」タスクは、ここに画像データを保存するだけにしよう。メモリにデータを書き込むのは、メモリカードに書き込むのよりもはるかに速いから、「写真を撮るタスク」は続けて4枚まで連続で写真を撮ることができるね。
「ファイル変換しメモリカードに画像を保存するタスク」は、あらかじめ決められたメモリアドレスに置かれている画像データをJPEGなどに変換し、メモリカードに保存する。アドレスがあらかじめ決まっているので、両タスク間で画像データのアドレスを連絡する手段を作らなくてもよくて、簡単だね。
ここまで、ヒープもスタックも、プログラム中で一時的に使用されるメモリ領域、ということは紹介したけど、まとめると、この2つにはこんな違いがあるんだ。
スタック
- コンパイラやOSが自動的に割り当て、解放を行う。
- Auto変数はスタックに確保される。(「七の巻:スタックってなあに?(1)」を参照)
- サイズは、プログラムをコンパイル、リンクする時点で決まっている。
ヒープ
- アプリケーションが、メモリが必要になった時に確保し、不要になったら解放するという処理を自分自身で行う必要がある。
- サイズは、メモリを確保する時に動的に指定することができる。
それじゃあ、これらをどうやって使い分ければいいのだろう?
アプリケーションを組む時に、スタックかヒープかを選択できる場面としては「変数の配置」があるんだ。まずはこれを例に見ていこう。
スタックは、OS やコンパイラが自動的に領域を割り当てるから、プログラムを組むのが楽というのがメリットになるよね。その一方で、使用できるサイズは決まっているので、使いすぎるとスタックがオーバーフローし、他の領域を書きつぶしてしまうという問題もあるんだ(「七の巻:スタックってなあに?(2)」を参照)。
逆に、不必要に大きなスタックを割り当てると、使われない領域が無駄に存在することになってしまって、組込みではよろしくないよね。つまり、スタックは比較的サイズが小さくて、特定の関数内でしか使わない変数に向いている。そうすれば、スタックのサイズを小さく設定することができるよね。例えば、下記の i や data のような変数がこれにあたる。

これに対してヒープは、使用するサイズとタイミングを、アプリケーションで決められるというのがメリットになる。組込み機器ではメモリの容量が限られており、使っていないメモリは解放して他の処理と共用で使うよう工夫するべきなので、比較的サイズか大きいもの、サイズが可変のものがヒープに適しているということだよね。例えば、ファイルを読み出す際のバッファを割り当てる場合で、

といった具合だ。
ファイルのサイズは毎回同じとは限らないので、ファイルサイズ分だけメモリをヒープに確保すれば、無駄にメモリを消費することはないよね。これをスタックで実現しようとすれば、ファイルサイズが最も大きくなる場合を想定しておかなければならない。例えば 1000~10000 バイトのファイルを扱うとすれば
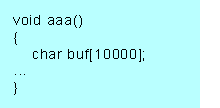
というように、最大に使用する想定でスタック変数を確保する必要があるね。
ファイルが 1000 バイトの場合は、9000 バイトは使用されない領域となってしまう。ただ、このような大きなサイズの配列は、関数内ではなく静的領域として確保する場合もあるよ。グローバル変数として、
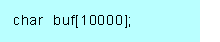
とするような場合だ。
この場合も、やっぱり最大に使用する想定で、あらかじめ割り当てておく必要があることには変わりはないんだけどね。ただし、ヒープメモリの確保、解放(malloc(), free())を頻繁に行うことはやめておいたほうがいいかもしれないよ。
フラグメンテーション(メモリが虫食い状態になる)を起こす原因となるからなんだ。フラグメンテーションについては、次回の講義で紹介してみようと思ってるので、お楽しみに。
OSを使う場合は、タスクごとのスタック割り当てや、ヒープメモリの管理はOSでやってくれるんだけど、OSを使用しないシステムの場合はどうなっているんだろう?

OSを使わない場合、スタックはシステム全体で一箇所を使用することになる。この場合も、スタック変数の割り当てなどはコンパイラやリンカがやってくれるので、プログラマーは特別な意識をする必要は無いんだけど、スタックのオーバーフローは注意してなくっちゃダメだよね。
ヒープメモリについては、mallocなどのメモリ割り当て関数が、開発環境(コンパイラ)に付属する標準ライブラリでサポートされている場合もあるんだけど、ない場合は自分で作る必要がある。また次回説明予定の「フラグメンテーション」を回避するために、あえてOSや標準ライブラリで用意されているヒープメモリ管理機能を使用しないで、自前でメモリ管理を行うこともあるんだよ。
限られたメモリで、頻繁にヒープメモリの確保と開放を行う必要があるシステムでは、このようなやり方になるし、当社のミドルウェアでもこの技術が使われているんだ。標準ライブラリでサポートされているメモリ管理は、例えばこんなふうになっている。
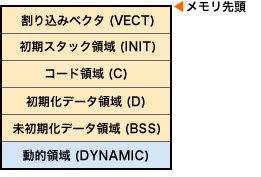
左記のように、「動的領域」というエリア(セクション)を割り当てておくんだ。
普通はこれはリンカで指定するようになっていて、開始アドレスやサイズをあらかじめ決めておく。スタック、ヒープ領域は、この「動的領域」を使用することになるね。
プログラマは、「動的領域」のアドレスとサイズを決め、スタックやヒープの配分も決めておかなければならないんだ。
今まで見てきたように、スタックは少なくすればスタックオーバーフローの危険性があるし、大きくすれば無駄に使われないメモリが存在することになるよね。スタックサイズの調節は、限られたメモリを最大限有効に使うための、プログラマーの腕の見せ所だ。
スタックサイズを決めるには、
- スタック変数のサイズや関数呼び出しの回数から計算する。
- スタックを多めに取っておいて、実際にプログラムを動作させて使用実績を測定する。
- 開発環境で用意されているスタックサイズ見積ツール活用する。
などの方法があるんだ。
今回は、スタックとヒープの特徴を踏まえて、どのように設定し、どのように使うかを話してみたよ。
スタックとヒープのもつ意味と違いが分かっていれば、それほど難しい内容じゃなかったよね。
さっきも言ったけど、次回はメモリを使う場合に注意しなくてはいけない「フラグメンテーション」について話していくよ。
-
- 第1回 組込みシステムのこれから
- 第2回 IoTの成功はセキュリティ次第
- 第3回 組込みでもGPUやFPGAと早めに親しんでおこう
- 第4回 電子産業の紅白歌合戦、CEATECで垣間見えた未来
- 第5回 小口開発案件の集合市場、IoTの歩き方(上)
- 第6回 小口開発案件の集合市場、IoTの歩き方(下)
- 第7回 徹底予習:AI時代の組込みシステム開発のお仕事
- 第8回 いまどきのセンサー(上):ありのままの状態を知る
- 第9回 いまどきのセンサー(下):データを賢く取捨選択する
- 第10回 組込みブロックチェーンの衝撃(上)
- 第11回 組込みブロックチェーンの衝撃(下)
- 第12回 エネルギーハーベスティングの使い所、使い方
- 第13回 「人を育てる」から「道具を育てる」へ、農業から学ぶAI有効活用法
- 第14回 CPS時代に組込みシステム開発に求められることとは
- 第15回 次世代車のE/Eアーキテクチャに見る組込みの進む道
- 第16回 RISC-Vが拓く専用プロセッサの時代
- 第17回 振動計測の大進化で、熟練エンジニアのスキルを広く身近に
-
- 零の巻:組込みというお仕事
- 壱の巻:2進数と16進数を覚えよう!
- 弐の巻:割り込みとポーリング
- 参の巻:printf()が使えない?
- 四の巻:これにもIntelが入ってるの?
- 五の巻:Endianってなに?
- 六の巻:マルチタスクとは
- 七の巻:スタックってなあに?(1)
- 七の巻:スタックってなあに?(2)
- 八の巻:メモリを壊してみましょう
- 九の巻:コードが消える?~最適化の罠~
- 拾の巻:例外が発生しました
- 拾壱の巻:コードサイズを聞かれたら
- 拾弐の巻:キャッシュは諸刃の剣
- 拾参の巻:デバイスにアクセスするには
- 拾四の巻:セキュリティってなに?(1)
- 拾四の巻:セキュリティってなに?(2)
- 拾四の巻:セキュリティってなに?(3)
- 拾五の巻 :DMA対応と言われたら(1)
- 拾五の巻 :DMA対応と言われたら(2)
- 拾六の巻:ヒープとスタック
- 拾七の巻:フラグメンテーション
- 拾八の巻:CPU起動とブートローダ
- 拾九の巻:kmとKByteの「kとK」
- ビリーへの質問:DMAとキャッシュの関係
- ビリーへの質問:スタックオーバーフローについて
- ビリーへの質問:CPUレジスタについて