
第9回 いまどきのセンサー(下):データを賢く取捨選択する
2017.12
 IoTシステム全体の価値を高める上で、その重要性が高まっているセンサー。前回は、現在のセンサーに見られる2つの進化軸のうち、「ありのままの状態を知るための機能」を強化することを目指す取り組みについて解説。現在のセンサーでは、正確で詳細なデータを取得するだけではなく、測定対象の状態を変えない計測が重要になっていることを紹介しました。
IoTシステム全体の価値を高める上で、その重要性が高まっているセンサー。前回は、現在のセンサーに見られる2つの進化軸のうち、「ありのままの状態を知るための機能」を強化することを目指す取り組みについて解説。現在のセンサーでは、正確で詳細なデータを取得するだけではなく、測定対象の状態を変えない計測が重要になっていることを紹介しました。
今回は、もうひとつの進化軸「データを賢く取捨選択するための機能」を強化するための取り組みを解説します。前回は、どちらかと言えば、取得できるデータを増やす取り組みでした。一方、今回は、折角取得したデータを取得したその場で絞り込んでしまう真逆の取り組みだと言えます。しかし、双方は一緒に組み合わせることで、IoTシステムの価値を高めることになります。
取得したデータの5%しか分析・活用していない
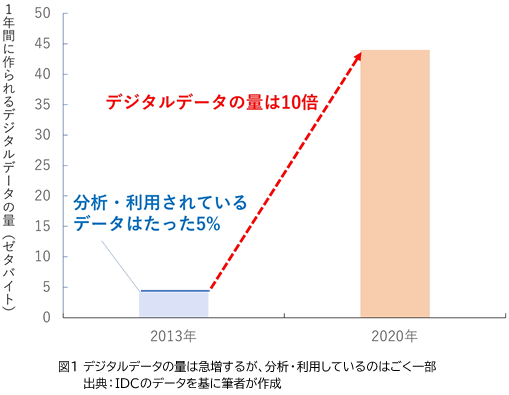
このコラムでも繰り返しお話ししていることですが、これからの情報システムは、IoTを活用して膨大なデータを集め、これをフル活用して新しい価値を生み出していくことになります。調査会社のIDCは、「2020年に地球上で1年間に生成されるデジタルデータは、44ゼタバイト(44兆ギガバイト)に達する」と予測しています。2013年に生成されたデータが4.4ゼタバイトとされていますから、7年で10倍に増えると予測しているわけです。
ところが、同調査会社は、「大半の企業では、収集したデータのうち、実際に解析され活用しているデータは平均5%程度にすぎない」(図1)とも言っています。現時点でさえ、収集したデータを利用し切ることができていないのに、これ以上多くのデータを集めて大丈夫なのでしょうか。そんな心配をよそに、IoTシステムを導入していけば、オフィスや工場、インフラなど、様々な場所から吸い上げるデータの量は爆発的に増加していきます。
そもそも、どうして取得したデータを有効活用できないのでしょうか。その理由の1つとして、取得したデータには不要なものが多く含まれ、その整理・理解に忙殺されて、本来活用すべきデータにまで手が回らないことが挙がります。解析されないまま放置されたデータの中に、重要な意味を持つものが多く埋もれていた可能性もあります。宝の持ち腐れとは、まさにこのことです。
また、たとえ重要なデータを見つけ出しても、そのデータがどのような条件で取得されたのか分からない場合もよくあります。解析に不可欠な付帯情報をタグ付けした、整理された状態になっていないため活用できないのです。活用が困難な状態にあるこうした生データを、「非構造化データ」と呼びます。
活用できないデータの増大は百害あって一利なし
こうした状況を放置したまま、センサーを様々な場所に大量設置し、IoTシステムの導入に踏み切っても、思い通りの効果が得られないのは明らかです。しかも、こうした莫大な非構造化データのすべてを、インターネット経由でやり取りし、サーバーに蓄えていたらどうなるでしょうか。何の価値も生まないどころか、不要なコスト高を招き、ネットのトラフィックをいたずらに混乱させるだけに終わってしまいます。
そこで、データを取得する現場で、有用なデータを選りすぐり、解析に利用しやすいかたちに加工しておくことが重要になります。これを私は、「蟹工船モデル」と呼んでいます。カニは食べられる部分が少なく、缶詰などにいずれ加工するのなら、採ったままのカニを漁場から持って帰るのは無駄です。そこで、船の上で加工してしまえば、輸送効率も上がり、早く売ることができます。しかも加工すれば付加価値も上がり、いいコトずくめです。ちなみに、蟹工船モデルという言葉は、全く一般的な言葉ではないので、ご注意を。
データを選りすぐり、加工する方法は、大きく2つの段階があります(図2)。
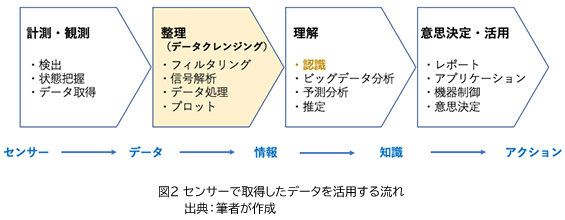
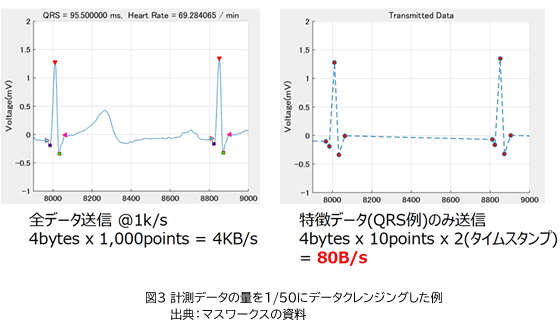
第1段階は、センサーで収集した生データから、必要な部分を取り出し、使いやすい形に整理しておく処理です。こうした処理を「データクレンジング」と呼びます。例えば、センサーから取得したデータには、明らかなノイズや、不要なデータがたくさん混じっています。こうした不要なデータは、フィルターで削っておく必要があります。また、あらかじめ設定しておいた条件を超えた値のデータだけ集めるとか、一定時間内の最大値と最小値だけを取得するといった、活用目的に合ったデータだけを粗ぶるいしておけば、データ容量を大幅に削減できます(図3)。平均値を出したり、換算式に基づいた演算を施して、活用しやすい量に変換しておく処理を行う場合も多いと思います。
さらに、収集したデータに、測定条件など付帯情報をタグ付けしたり、複数のセンサーから集めたデータを統合するとき、同じ表現形式になるように規格化して、整理しておくことも重要です。これらの処理は、負荷自体は大きなものではありません。しかし、取得するデータの量が多くなると、それなりに負荷が増してくるため、相応の性能のシステムが必要になってきます。
こうした処理の内容は、データを取得する現場環境を熟知し、同時に活用目的もよく理解している人が決める必要があります。センサーで取得した生データの中のどの部分が有用な情報なのかを見極めなければならないからです。IoTシステムで用いるセンサーでは、こうしたデータクレンジングがとても重要であり、システムの価値を決めます。単に、データ処理を実行する組込みシステムを効率的に開発できるだけでは、価値あるセンサーにはなりません。
データ解析を現場で済ませて迅速に情報活用
第2段階は、データの解析まで現場で済ませて、意味のある情報に変えてしまおうというものです。特に画像や音声のデータを解析して、データの内容を認識する例が増えています。画像認識や音声認識が、その代表例です。データクレンジングを済ませて、解析はクラウド上の大きな計算能力で実行するシステムも多いと思います。しかし、解析まで現場で済ませたい用途も実は多くあるのです。
例えば、工場のラインの稼働状況をモニタリングし、対処すべき事態が発生したら自動的に対処するようなシステム。こうしたシステムでは、センサーによるデータの収集から、データクレンジング、解析、対応までを短時間で行うリアルタイム性が要求されます。自動運転車やロボットも同様です。これらの応用では、いくら解析能力が高くても、通信の遅延を覚悟してクラウド上での解析に頼ることはできません。また、セキュリティーやプライバシー上の理由から、センサーで取得した情報をネットに流したくない応用もあります。機密性の高い情報を扱う開発や生産のデータを扱うシステムや、医療関係のシステムがその代表例でしょう。
解析処理を入れることで、より高度なデータクレンジングもできるようになる可能性もあります。例えば、近年の音声認識技術の進歩と同時に、雑多な音の中から特定の音源を高度に分別する技術が確立されてきました(図4)。1つの機器に複数のマイクを搭載し、それぞれに入力した音の違いを分析することで、音源を分離できます。人間の耳は,左右1対で音源の方向を把握していますが、音を取り込むマイクの数をさらに増やせば、位置をより正確に決めることができるというわけです。聖徳太子は、10人が一度に発した声を聞き分けることができたという伝説がありますが、同じ能力を機械で実現できます。どんなに騒がしい環境でも、音源ごとに音を分解できれば、意味のある情報だけを抽出できるようになります。

近年では、デジタルカメラで、人がいる場所にピントを合わせたり、笑顔になった時だけシャッターを切るといった高度な認識機能が実現されるようになりました。今後、AI関連の処理を小型、低消費電力のチップで実行できるようになれば、さらに高度な解析機能をセンサーに付加できるようになるでしょう。実際、こうした用途での利用を想定したAIチップの開発が活発化しています。
2回にわたって、IoT時代のセンサーが、どのように進化しているのか、「ありのままの状態を知るための機能」と「データを賢く取捨選択するための機能」という、センサーの新しい進化軸に注目して解説してきました。IoTのエッジ側機器の開発では、センサーの高精度化、小型化、低消費電力化だけにとどまらない、新たな価値基準が出てきています。こうした視点を開発時に盛り込み、IoTシステムの価値を高めていくことが、とても大切になってきています。
![]()